梯度下降原理与实现
梯度下降原理与实现
学习新的知识,我往往喜欢由点及面梳理其发展脉络,这有助于我构建一个知识体系,并不断向其中添加细节。
(一)Why choose梯度下降?
既然深度学习本质是数学方程,很容易想到的一种方式就是凸优化,比如二次函数寻找极值点的过程。
在基于梯度的下降之前,也有过基于坐标的优化,形式上就是暴力得迭代所有可能的值。
得益于反向传播,基于梯度下降的优化才成为可能。依据梯度确定参数优化的方向,显然,相比暴力法时间复杂度更低。
(二)梯度下降理论
数学公式
其中是学习率,为待更新的参数,为损失函数,为多维空间中函数上升最快的方向。
推导过程

这里直接放的李沐老师课程中的推导,有兴趣可以看看。
(三)梯度下降实现
示例代码
1 | |
(四)常用梯度下降
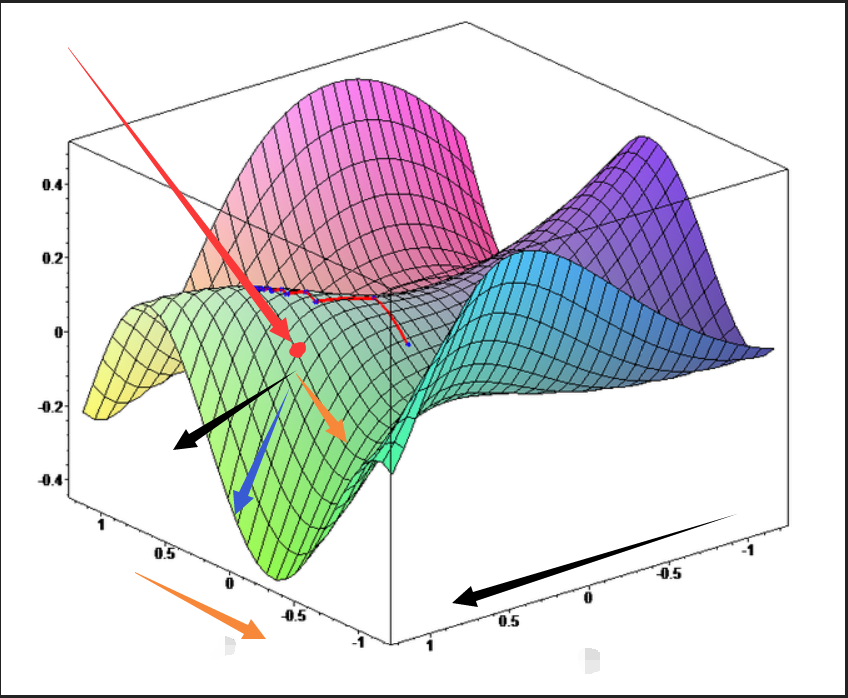
接进行梯度下降,由于张量的高阶特性,往往会使神经网络收敛在鞍点或者说局部最优(因为一个维度上的最优点不一定是另一个维度的最优点),而非最好的结果。因此如何跳出局部最优,如何找到全局最优一直是各类梯度下降算法研究的核心。
SGD
核心就是使用随机的值进行迭代。后期的一些SGD变体,也通过添加动量等方式加快收敛速度和跳出鞍点。
pytorch中关于SGD的实现,torch.optim.SGD。
Adam
Adam相较于SGD,核心就是为每个超参数添加了自适应学习率,快速收敛且无需过多调参。
pytorch中关于Adam的实现,torch.optim.Adam。
梯度下降原理与实现
https://mrkeanu-v.github.io/2023/11/20/梯度下降算法原理与实现/